Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Los elementos marcados (versión preliminar) de este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se proporciona sin un contrato de nivel de servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no se admitan o que tengan funcionalidades restringidas. Para obtener más información, vea Supplemental Terms of Use for Microsoft Azure Previews.
Pruebe los modelos y agentes de IA generativos mediante la ejecución de evaluaciones que miden el rendimiento, la calidad y la seguridad. Use evaluaciones antes de la implementación para validar el comportamiento o después de la implementación para supervisar la calidad de producción. Las evaluaciones ejecutan su modelo o agente con datos de prueba y califican los resultados mediante evaluadores integrados o personalizados.
En este artículo se muestra cómo crear y ejecutar evaluaciones en el portal de Foundry.
Requisitos previos
Una suscripción a Azure. Crear uno gratis.
Un proyecto de Microsoft Foundry. Cree un proyecto si no tiene uno.
Uno de los siguientes, según su objetivo de evaluación:
- Evaluación de agente: un agente de tu proyecto.
- Evaluación del modelo: un modelo implementado o un modelo disponible con acceso instantáneo.
- Evaluación del conjunto de datos: un conjunto de datos de prueba en formato CSV o JSONL que contiene salidas de agente o modelo preexistentes.
Una conexión de OpenAI Azure con un modelo GPT implementado (por ejemplo,
gpt-4.1-mini). Necesario para las evaluaciones de calidad asistidas por IA.Rol de usuario de Foundry en el proyecto Foundry. Para obtener más información, consulte control de acceso basado en roles para Microsoft Foundry.
Importante
Recientemente se ha cambiado el nombre de los roles RBAC de Foundry. Foundry User, Foundry Owner, Foundry Account Owner y Foundry Project Manager se llamaban anteriormente Usuario de Azure AI, Propietario de Azure AI, Propietario de la cuenta de Azure AI y Administrador de proyectos de Azure AI. Es posible que siga viendo los nombres anteriores en algunos lugares mientras se implementa el cambio de nombre. El cambio de nombre no modifica los identificadores de rol y los permisos principales.
Elección de un enfoque de evaluación
Seleccione un enfoque de evaluación basado en lo que desea probar:
| Objetivo | Ámbito | Origen de datos | Más adecuado para |
|---|---|---|---|
| Agent | Conversaciones completas | Datos simulados | Probar el comportamiento del agente de un extremo a otro con escenarios sintéticos antes de la implementación. |
| Agent | Conversaciones completas | Conversaciones existentes | Evaluación de interacciones reales del usuario para supervisar la calidad de producción. |
| Agent | Turnos individuales | Conjunto de datos existente | Depuración de respuestas específicas del agente, prueba del uso de herramientas, análisis detallado. |
| Agent | Turnos individuales | Datos sintéticos | Probar escenarios de Q&A o RAG de un solo turno con consultas generadas. |
| Agent | Turnos individuales | Trazas existentes | Evaluar seguimientos históricos del agente en su proyecto. |
| Modelo | Turnos individuales | Datos sintéticos | Pruebe las finalizaciones del modelo con indicaciones generadas. |
| Modelo | Turnos individuales | Conjunto de datos existente | Evaluación comparativa del rendimiento del modelo con respecto a un conjunto de pruebas cuidadosamente seleccionado. |
| Dataset | Turnos individuales | (El conjunto de datos es el destino) | Evaluar las salidas preexistentes sin volver a ejecutar el modelo o el agente. |
Tip
Comience con conversaciones > completas del agente > Datos simulados para probar el comportamiento del agente en escenarios controlados. Utiliza Conversaciones existentes una vez que tu agente esté en producción para supervisar el rendimiento en el mundo real.
Creación de una evaluación
Puede iniciar una evaluación desde varios lugares en el portal de Foundry:
- Página de evaluación: en el panel izquierdo, seleccione Crear evaluación>.
- Página Modelos: vaya al modelo, seleccione la pestaña Evaluación y, a continuación, seleccione Crear.
- Página Agentes: vaya al agente, seleccione la pestaña Evaluación y, a continuación, seleccione Crear.
- Área de juegos del agente: vaya al agente, seleccione la pestaña Área de juegos y, a continuación, seleccione Métricas>Ejecutar evaluación completa.
Paso 1: Seleccionar destino de evaluación
Al crear una evaluación, elija primero el destino de evaluación. El destino determina en qué se ejecuta la evaluación:
| Objetivo | Description |
|---|---|
| Agent | Evalúa la salida generada por el agente seleccionado y la entrada definida por el usuario. Funciona tanto para agentes de instrucciones como para agentes hospedados. |
| Modelo | Evalúa la salida generada por el modelo seleccionado y la solicitud definida por el usuario. |
| Dataset | Evalúa las salidas del modelo o agente preexistentes de un conjunto de datos de prueba. |
| Traces | Evalúa las interacciones del agente ya capturadas en Application Insights. Seleccione el agente y el intervalo de tiempo, y el portal recupera los seguimientos coincidentes para su evaluación. Para ver el SDK equivalente, consulte Evaluación de seguimiento. |
Tip
Acceso instantáneo: son modelos que no requieren implementación y que se pueden usar inmediatamente sin crear una implementación. Al crear una evaluación, puede seleccionar un modelo instantáneo como destino de evaluación o el modelo de juez directamente desde el selector de modelos.
Paso 2: Seleccionar el ámbito de evaluación
Nota
Este paso solo aparece para los destinos del agente y del conjunto de datos . Las evaluaciones de modelos siempre usan turnos individuales.
Elija cómo desea evaluar el rendimiento del agente:
| Ámbito | Description | Más adecuado para |
|---|---|---|
| Conversaciones completas (versión preliminar) | Evalúa conversaciones completas de varios turnos de principio a fin. Mide la calidad general de la conversación, la finalización de tareas y la satisfacción del usuario. | Evaluación de las experiencias integrales del agente, la satisfacción del cliente y el flujo de la conversación. |
| Turnos individuales | Evalúa las respuestas individuales del agente dentro de las conversaciones. Mide métricas por turno, como la precisión de la selección de herramientas y la calidad de respuesta. | Depuración de comportamientos específicos del agente, pruebas de uso de herramientas y análisis detallados. |
Paso 3: Selección del origen de datos
Las opciones del origen de datos dependen del ámbito y el destino de evaluación.
Para las evaluaciones de conversaciones (conversaciones completas del agente >) (versión preliminar)
Elija dónde proceden los datos de la conversación:
Datos simulados
Genere conversaciones sintéticas mediante la ejecución del agente en descripciones de escenarios a partir de un conjunto de datos. Use esta opción para probar el comportamiento del agente en escenarios controlados antes de la implementación.
Seleccione Datos simulados.
Seleccione Generar para abrir el cuadro de diálogo de configuración de simulación.
Seleccione el archivo: elija un conjunto de datos que contenga descripciones de escenarios. Cada fila del conjunto de datos describe un escenario que se usa para generar una conversación simulada.
Seleccionar modelo: elija el modelo que simula al usuario en la conversación:
-
gpt-4.1(recomendado para escenarios complejos) gpt-4ogpt-4o-minigpt-4.1-mini
-
Configuración de las opciones de simulación:
- Número de conversaciones simuladas por escenario: cuántas conversaciones se van a generar para cada fila del conjunto de datos (1-5). Varias conversaciones por escenario ayudan a identificar la varianza en el comportamiento del agente.
- Número de turnos por conversación: número máximo permitido por conversación (1-50). La conversación finaliza cuando se completa la tarea o se alcanza este límite.
Seleccione Confirmar para guardar la configuración de simulación.

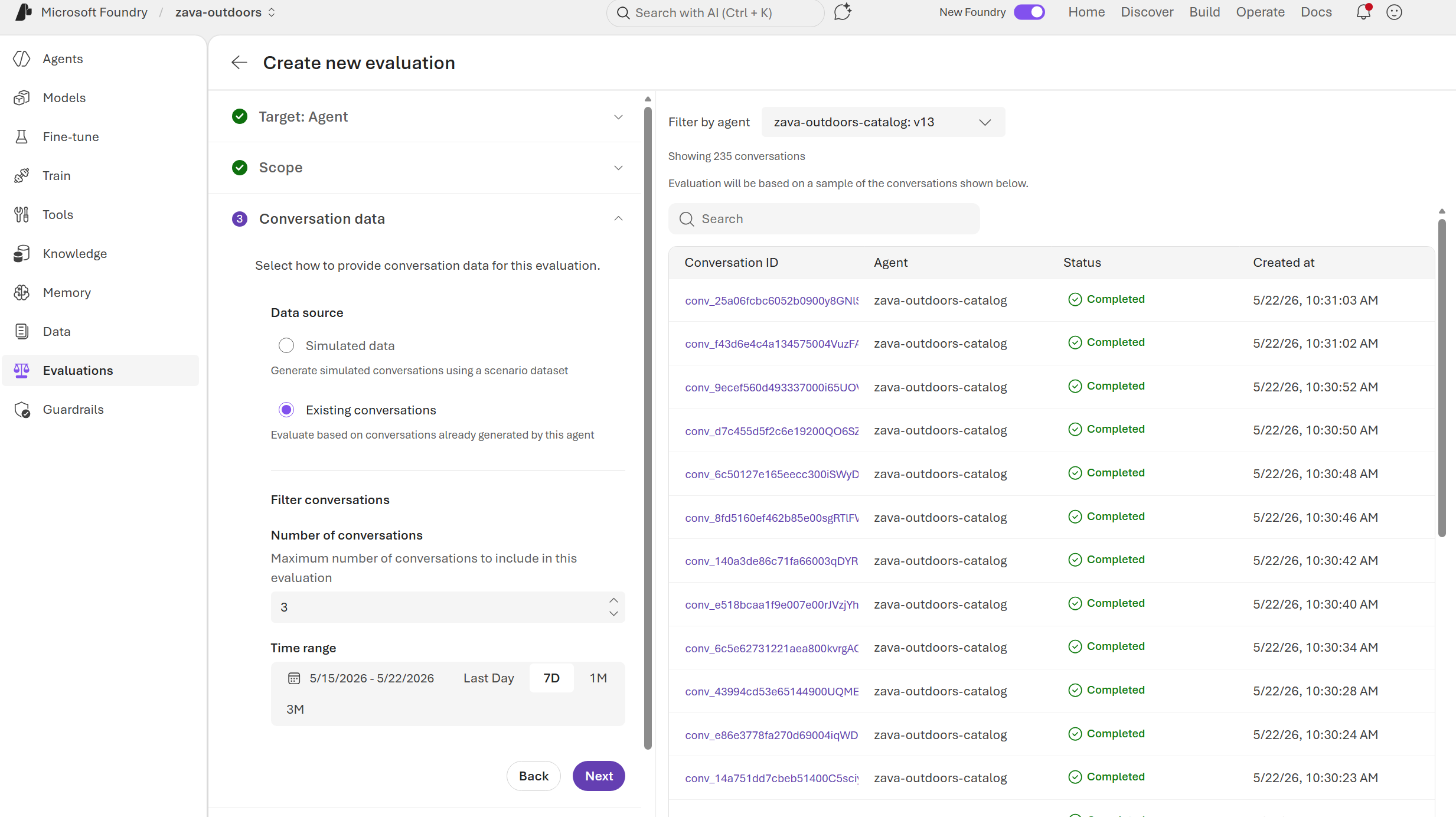
Conversaciones existentes
Evalúe las conversaciones reales que el agente ya tenía con los usuarios.
- Seleccione Conversaciones existentes.
- Configure las opciones de filtrado:
- Número de conversaciones: número máximo de conversaciones que se van a muestrear desde el intervalo de fechas (1-100).
- Intervalo de tiempo: filtre las conversaciones por período de tiempo. Use filtros rápidos (Último día, 7D, 1M, 3M) o seleccione un intervalo de fechas personalizado.
- Examine y seleccione conversaciones específicas que se van a incluir en la evaluación.
Para la evaluación de cada turno
Elija dónde proceden los datos de evaluación:
Datos sintéticos
Genere consultas de prueba mediante IA. Seleccione Sintético y configure el número de filas y una instrucción para describir los datos que se van a generar. También puede cargar archivos para mejorar la relevancia.
Nota
La generación de datos sintéticos requiere un modelo con la funcionalidad de la API de respuestas. Para obtener disponibilidad, consulte Disponibilidad de la región de la API de respuestas.
Conjunto de datos existente
Use un conjunto de datos preparado en formato CSV o JSONL. Seleccione Conjunto de datos existente y elija un archivo de los recursos de datos del proyecto. Solo se admiten formatos de archivo CSV y JSONL.
Trazas existentes (solo para el agente)
Evalúe seguimientos históricos del agente en su proyecto. Seleccione Seguimientos existentes y filtre por intervalo de fechas para seleccionar seguimientos.
Contenido multimodal (vista previa)
Todos los destinos de evaluación admiten contenido de imagen y audio. Cada tipo de contenido usa un esquema JSONL específico:
Contenido de la imagen:
-
image_url: la imagen como un URI de datos (por ejemplo,data:image/png;base64,...) o una dirección URL de acceso público. -
caption: una descripción de texto del contenido de la imagen.
{"image_url": "data:image/png;base64,iVBOR...", "caption": "A red to blue color gradient"}
Contenido de audio:
-
audio_data: el audio como un URI de datos con datos WAV codificados en base64 (por ejemplo,data:audio/wav;base64,...). -
expected: una descripción de texto del contenido de audio esperado.
Nota
Actualmente solo se admite el formato de audio WAV.
{"audio_data": "data:audio/wav;base64,UklGR...", "expected": "A short beep tone at 440 Hz"}
Los conjuntos de datos también pueden usar el formato de conversación de mensajes de chat, donde los datos de audio e imagen se insertan dentro de una sola columna de mensaje de chat como URI de datos o direcciones URL accesibles públicamente.
En el ejemplo siguiente se muestra una columna de conjunto de datos de conversación con contenido de audio y imagen incrustado:
[
{
"role": "system",
"content": "..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are in these images?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/path/image.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,iVBORw0KGgo..."
}
}
]
},
{
"role": "assistant",
"content": "..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Tell me the tones for the voices?"
},
{
"type": "input_audio",
"input_audio": {
"data": "https://example.com/path/voice.wav",
"format": "wav"
}
},
{
"type": "input_audio",
"input_audio": {
"data": "data:audio/wav;base64,UklGRigAAA...",
"format": "wav"
}
}
]
}
]
Puede obtener una vista previa de las imágenes y reproducir clips de audio directamente en el flujo de creación de la evaluación y en la vista de resultados de evaluación.
Paso 4: Configurar agentes
Nota
Este paso solo aparece para las evaluaciones de Agente.
Personalice cómo se comporta el agente durante la evaluación:
- Revise la lista de agentes implicados en la evaluación.
- Para cada agente, seleccione Configurar para personalizar su comportamiento:
- Aviso del sistema: modifique las instrucciones del agente para la evaluación.
- Mensaje de usuario: especifique cómo se envía cada elemento de conjunto de datos al agente durante la evaluación.
- La ejecución de evaluación mantiene las configuraciones del agente.
Configuración del mensaje de usuario
El prompt del usuario define cómo se pasan las entradas de prueba a tu agente. De forma predeterminada, el portal usa {{item.query}} para pasar la consulta del conjunto de datos directamente al agente.
En la mayoría de los casos, puede usar el valor predeterminado. Solo cambie este valor si el agente espera un formato de entrada diferente. Por ejemplo, si el agente usa un protocolo de agente hospedado o requiere una entrada estructurada con campos adicionales.
Patrones comunes:
| Formato | Cuándo se deben usar |
|---|---|
{{item.query}} |
Predeterminada. Pasa directamente el campo de consulta desde el conjunto de datos. |
{{item.messages}} |
Para los agentes que esperan el historial de conversaciones como entrada. |
| JSON personalizado | Para agentes hospedados o API que requieren cuerpos de solicitud estructurados. |
Tip
Use avisos personalizados para probar casos perimetrales o escenarios específicos que podrían no producirse de forma natural en el conjunto de datos.
Paso 5: Configurar la asignación de campos
Nota
Este paso aparece cuando se usan datos existentes (conversaciones existentes, conjuntos de datos existentes o seguimientos existentes).
Asigne los campos de datos a los campos que espera cada evaluador. Los campos obligatorios dependen del ámbito de evaluación.
Para evaluaciones de conversaciones (multiturno)
| Campo | Description | Obligatorio |
|---|---|---|
| mensajes | Los mensajes de conversación en formato de chat. | Sí |
| tool_definitions | Definiciones de herramientas o funciones disponibles para el agente. | Sí |
Para las evaluaciones de turnos individuales (un solo turno)
| Campo | Description | Obligatorio |
|---|---|---|
| consulta | La consulta o la solicitud del usuario. | Sí |
| response | El modelo o la respuesta del agente. | Sí |
| context | Contexto recuperado para escenarios RAG. | No |
| ground_truth | Se esperaba una respuesta correcta para la comparación. | No |
| tool_calls | Llamadas a herramientas realizadas por el agente. | No |
| tool_definitions | Definiciones de herramientas disponibles. | No |
El portal intenta asignar automáticamente los campos del conjunto de datos. Si un campo se muestra como Sin asignar, seleccione la lista desplegable para asignar manualmente una columna del conjunto de datos.
Nota
Los campos obligatorios se marcan con un asterisco (*). Los evaluadores fallan si los campos obligatorios se dejan sin asignar.
Paso 6: Seleccionar criterios de prueba
Seleccione los evaluadores que se van a usar para la evaluación. Microsoft Foundry proporciona tres categorías de evaluadores integrados. Los evaluadores disponibles dependen del ámbito de evaluación.
Evaluadores de agentes
Evalúe la eficacia de los agentes para controlar las tareas, las herramientas y la intención del usuario. Disponible solo para el ámbito de turnos individuales.
| Evaluador | Description |
|---|---|
| Resolución de intenciones | Mide si el agente identificó y solucionó correctamente la intención del usuario. |
| Cumplimiento de tareas | Mide hasta qué punto el agente siguió las instrucciones y restricciones. |
| Éxito en la ejecución de la herramienta | Evalúa si las llamadas de herramienta se ejecutaron correctamente. |
| Selección de herramientas | Mide si el agente seleccionó las herramientas adecuadas para la tarea. |
| Uso de la salida de la herramienta | Evalúa hasta qué punto el agente utilizó eficazmente los resultados de la herramienta en sus respuestas. |
| Precisión de entrada de la herramienta | Mide si el agente proporcionó entradas correctas a las herramientas. |
| Precisión de las invocaciones de herramientas | Precisión general del uso de herramientas. |
Evaluadores de calidad
Mida la calidad general de las respuestas generadas. La mayoría de los evaluadores de calidad están disponibles para todos los ámbitos de evaluación. Los evaluadores marcados con ★ admiten análisis a nivel de conversación y de turno.
| Evaluador | Description | Soporte para conversaciones |
|---|---|---|
| Satisfacción del cliente | Predice la satisfacción del usuario con la interacción del agente. | ★ |
| Finalización de tareas | Evalúa si el agente completó correctamente la tarea solicitada. | ★ |
| Coherence | Mide el flujo lógico y la coherencia de las respuestas. | ★ |
| Groundedness | Mide si las respuestas se basan en el contexto proporcionado. | ★ |
| Integridad de la respuesta | Evalúa si las respuestas abordan por completo las consultas de usuario. | — |
| Fluency | Evalúa la calidad del lenguaje natural. | — |
| Relevance | Evalúa cómo son las respuestas pertinentes a la consulta. | — |
Evaluadores de seguridad
Identificar posibles riesgos de contenido y seguridad. Disponible solo para el ámbito de turnos individuales.
| Evaluador | Description |
|---|---|
| Violencia | Detecta contenido violento en las respuestas. |
| Sexual | Detecta contenido sexual. |
| Autolesión | Detecta contenido relacionado con autolesiones. |
| Odio/injusticia | Detecta contenido odioso o sesgado. |
El portal preselecciona los evaluadores recomendados en función del ámbito y el destino de evaluación:
- Conversaciones completas: Satisfacción del cliente, Finalización de tareas, Coherencia, Base
- Turnos individuales (datos existentes): todos los evaluadores de agente más los evaluadores de calidad y seguridad
- Turnos individuales (sintéticos/trazas): Relevancia, Fundamentación, Fluidez, Coherencia
Tip
Puede agregar o quitar evaluadores según sea necesario. Seleccione Evaluadores personalizados para usar evaluadores definidos en el proyecto.
Paso 7: Revisar y enviar
- Escriba un nombre para la evaluación.
- Revise la configuración:
- Destino y ámbito de evaluación
- Origen de datos y conjunto de datos
- Evaluadores seleccionados
- Asignación de campos (si corresponde)
- Seleccione Enviar para iniciar la evaluación.
Después de enviar, se inicia la ejecución de la evaluación. Las evaluaciones normalmente se completan en unos minutos, en función del tamaño del conjunto de datos y del número de conversaciones que se simulan.
Para comprobar que la evaluación se inició correctamente:
- En el panel izquierdo, seleccione Evaluación.
- Busque la evaluación en la lista. La columna Estado muestra el estado actual:
- En curso: la evaluación se está ejecutando.
- Completado: la evaluación finalizó correctamente.
- Parcial: algunos evaluadores se completaron correctamente, pero otros fallaron.
- Error: la evaluación encontró un error.
Para ver los resultados detallados, seleccione el nombre de evaluación o vea Ver los resultados de la evaluación.
Tip
Para los flujos de trabajo de evaluación mediante programación, use el SDK de evaluación de IA de Azure. Consulte Ejecución de la evaluación por lotes con el SDK.
Solución de problemas
La evaluación supera el tiempo de espera o se ejecuta lentamente
- Reduzca el número de conversaciones o filas del conjunto de datos.
- En el caso de las simulaciones, reduzca los turnos máximos por conversación.
- Compruebe que el modelo de evaluación tiene cuota suficiente.
Errores de asignación de campos
- Compruebe que el conjunto de datos contiene las columnas necesarias para el ámbito de evaluación.
- Para las evaluaciones de conversación, asegúrese de que la columna de mensajes contiene mensajes de chat con el formato correcto.
- Compruebe que los nombres de columna del conjunto de datos coincidan con los nombres de campo esperados.
Se ha superado la cuota del modelo
- El modelo de evaluación que se usa para las evaluaciones asistidas por IA se descuenta de la cuota de Azure OpenAI.
- Use un conjunto de datos más pequeño o espere a que se actualice la cuota.
- Considere la posibilidad de usar
gpt-4.1-minien lugar degpt-4.1para evaluaciones rentables.
procedimientos recomendados
Para las evaluaciones basadas en simulación
- Inicio pequeño: comience con 1 conversación por escenario y 5-10 turnos para validar la configuración antes de escalar verticalmente.
- Diversos escenarios: incluya una variedad de descripciones de escenarios para probar diferentes funcionalidades del agente.
- Iterar sobre las indicaciones: si los agentes se comportan de forma inesperada, use el paso Configurar agentes para ajustar las indicaciones.
Para evaluaciones de conversaciones existentes
- Ejemplo representativo: seleccione conversaciones que representen interacciones típicas del usuario.
- Incluye casos límite: no evalúes solo las conversaciones exitosas; incluye también escenarios complejos.
- Evaluación regular: programe evaluaciones periódicas para realizar un seguimiento del rendimiento del agente a lo largo del tiempo.
Para las evaluaciones de modelos
- Conjuntos de datos de pruebas comparativas: use conjuntos de datos estandarizados para comparar el rendimiento del modelo entre versiones.
- Pruebe tanto las opciones implementadas como las de acceso instantáneo: Compare sus implementaciones ajustadas con los modelos base.
Para las evaluaciones de conjuntos de datos
- Precalcular salidas: genere salidas sin conexión y evalúelas de forma masiva para mejorar la eficiencia de costes.
- Versión de los conjuntos de datos: realice un seguimiento de la versión del conjunto de datos que generó los resultados de la evaluación.
Sugerencias generales
- Comparar evaluadores: ejecute los mismos datos a través de varios evaluadores para obtener una vista completa.
- Seguimiento de tendencias: use el historial de evaluación para identificar mejoras de rendimiento o regresiones.
- Actuar sobre los resultados: use información de evaluación para refinar las indicaciones del agente, las definiciones de herramientas y las configuraciones.
Contenido relacionado
Obtenga más información sobre cómo evaluar los modelos y agentes de ia generativa: