Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Visualización actual:![]() Nueva versión - Cambio a la versión del portal de Foundry clásico
Nueva versión - Cambio a la versión del portal de Foundry clásico
Spillover gestiona las fluctuaciones del tráfico en los despliegues aprovisionados redirigiendo automáticamente las solicitudes que exceden la capacidad a un despliegue estándar correspondiente. Cuando la implementación aprovisionada se usa por completo y devuelve respuestas que no son de 200 (por ejemplo, 429 cuando se agotan las PTU), el desbordamiento redirige esas solicitudes a la implementación estándar, lo que ayuda a reducir las interrupciones durante las ráfagas de tráfico. Esta funcionalidad opcional se puede configurar para todas las solicitudes de una implementación o gestionar por solicitud.
Requisitos previos
- Una suscripción Azure. Cree uno gratis.
- Una implementación administrada aprovisionada y una implementación estándar en el mismo recurso de Foundry.
- CLI de Azure instalado para ejemplos de API REST o acceso al portal de Foundry.
- La variable de entorno
AZURE_OPENAI_ENDPOINTestablecida en la dirección URL del punto de conexión de OpenAI de Azure. - Colaborador de Cognitive Services o jerarquía superior en el recurso de Foundry para crear o modificar implementaciones.
Habilitar el desbordamiento para todas las solicitudes en una implementación preconfigurada
-
Inicie sesión en Microsoft Foundry. Asegúrese de que el interruptor New Foundry está activado. Estos pasos hacen referencia a Foundry (new).

Seleccione la suscripción y el recurso en la región donde tiene cuota.
Seleccione Detectar en el panel de navegación superior derecho y, a continuación, Modelos en el panel izquierdo.
Seleccione el filtro Colecciones y filtre por Directo desde Azure para ver los modelos vendidos directamente por Azure. Algunos de estos modelos admiten la opción de implementación con rendimiento aprovisionado.
Seleccione el modelo que desea implementar para abrir su tarjeta de modelo.
Seleccione Implementar>configuración personalizada para configurar la implementación. En el menú desplegable Tipo de implementación se enumeran los tipos de implementación aprovisionados que están disponibles para el modelo seleccionado.
Nota
Para habilitar el desbordamiento, la cuenta debe tener al menos una implementación activa de pago por uso que coincida con el modelo y la versión de la implementación aprovisionada actual.
Establezca el tipo de implementación en una de las opciones aprovisionadas, por ejemplo, rendimiento aprovisionado global.
Seleccione Desbordamiento de tráfico para habilitar el desbordamiento de la implementación aprovisionada.
Habilitar el desbordamiento para las solicitudes de inferencia selectas
Para habilitar selectivamente el desbordamiento por cada solicitud, establezca el encabezado de solicitud de inferencia x-ms-spillover-deployment en el objetivo de implementación estándar para las solicitudes de desbordamiento. Si el encabezado x-ms-spillover-deployment no se ha aplicado en una solicitud determinada, el desbordamiento se iniciará en caso de una respuesta que no sea 200. El uso u omisión de este encabezado proporciona la flexibilidad para decidir cuándo iniciar o no el desbordamiento para una carga de trabajo o escenario determinado.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/spillover-ptu-deployment/chat/completions?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "x-ms-spillover-deployment: spillover-standard-deployment" \
-H 'Authorization: Bearer YOUR_AUTH_TOKEN' \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure services support this too?"}]}'
Una solicitud correcta devuelve el estado 200 HTTP con la respuesta de finalización del chat. Si se produce un desbordamiento, el encabezado x-ms-spillover-from-deployment se incluye en la respuesta.
Referencia:Crear finalización de chat
Nota
Si la funcionalidad de desbordamiento está habilitada para la implementación mediante la spilloverDeploymentName propiedad y también habilitada en el nivel de solicitud mediante el x-ms-spillover-deployment encabezado , el sistema tiene como valor predeterminado la configuración de la propiedad de implementación. Si desea asegurarse de que spillover solo esté habilitado para cada solicitud, no establezca la propiedad spilloverDeploymentName en la implementación aprovisionada y dependa únicamente del encabezado x-ms-spillover-deployment para cada solicitud.
Identificar solicitudes de desbordamiento
Los siguientes encabezados de respuesta HTTP indican que se ha desbordado una solicitud específica:
-
x-ms-spillover-from-deployment: contiene el nombre de implementación de PTU. La presencia de este encabezado indica que la solicitud es una solicitud derivada. -
x-ms-deployment-name: contiene el nombre de la implementación que atiende la solicitud. Si la solicitud se desborda, el nombre de la implementación es el nombre de la implementación estándar. -
x-ms-spillover-errorse devuelve en cualquier solicitud que exceda la capacidad y contiene el código de respuesta de la implementación con capacidad aprovisionada que provocó el desbordamiento (por ejemplo, 429, 500 o 503). Está presente tanto si el intento de desbordamiento acaba teniendo éxito como si no.
Para una solicitud desbordada, si la implementación estándar tampoco puede atenderla, se devuelve a quien realiza la llamada la respuesta de la implementación estándar (incluidos el código de estado y el cuerpo). Las cabeceras x-ms-spillover-from-deployment y x-ms-spillover-error siguen estando presentes, por lo que quien realiza la llamada puede distinguir un fallo por desbordamiento de un fallo directo de despliegue estándar.
Control de uso del desbordamiento
El desbordamiento de tráfico se basa en una combinación de implementaciones preaprovisionadas y estándar para gestionar los excesos de tráfico, por lo que la supervisión puede realizarse en el nivel de cada implementación. Para ver cuántas peticiones se procesaron en la implementación aprovisionada principal en comparación con la implementación estándar de desbordamiento, aplique la función de división en las métricas de Azure Monitor para ver las peticiones procesadas por cada implementación y sus respectivos códigos de estado. Del mismo modo, use la característica de división para ver cuántos tokens se procesaron en la implementación aprovisionada principal frente a la implementación estándar de desbordamiento durante un período de tiempo determinado.
El siguiente gráfico de métricas de Azure Monitor proporciona un ejemplo de la división de solicitudes entre la implementación aprovisionada principal y la implementación estándar de desbordamiento cuando se inicia el desbordamiento. Para crear un gráfico, vaya al recurso en el portal Azure.
Seleccione Supervisión de>métricas en el menú de navegación izquierdo.
Agregue la métrica
Azure OpenAI Requests.captura de pantalla que muestra las métricas de un ejemplo de desbordamiento básico en el portal de Azure.
Seleccione Aplicar división y aplique las divisiones
ModelDeploymentNameyStatusCodea la métricaAzure OpenAI Requests. Esto muestra un gráfico con el200(éxito) y400(código de error) que se generaron para su recurso. El recuento del código de error es actualmente cero en el gráfico.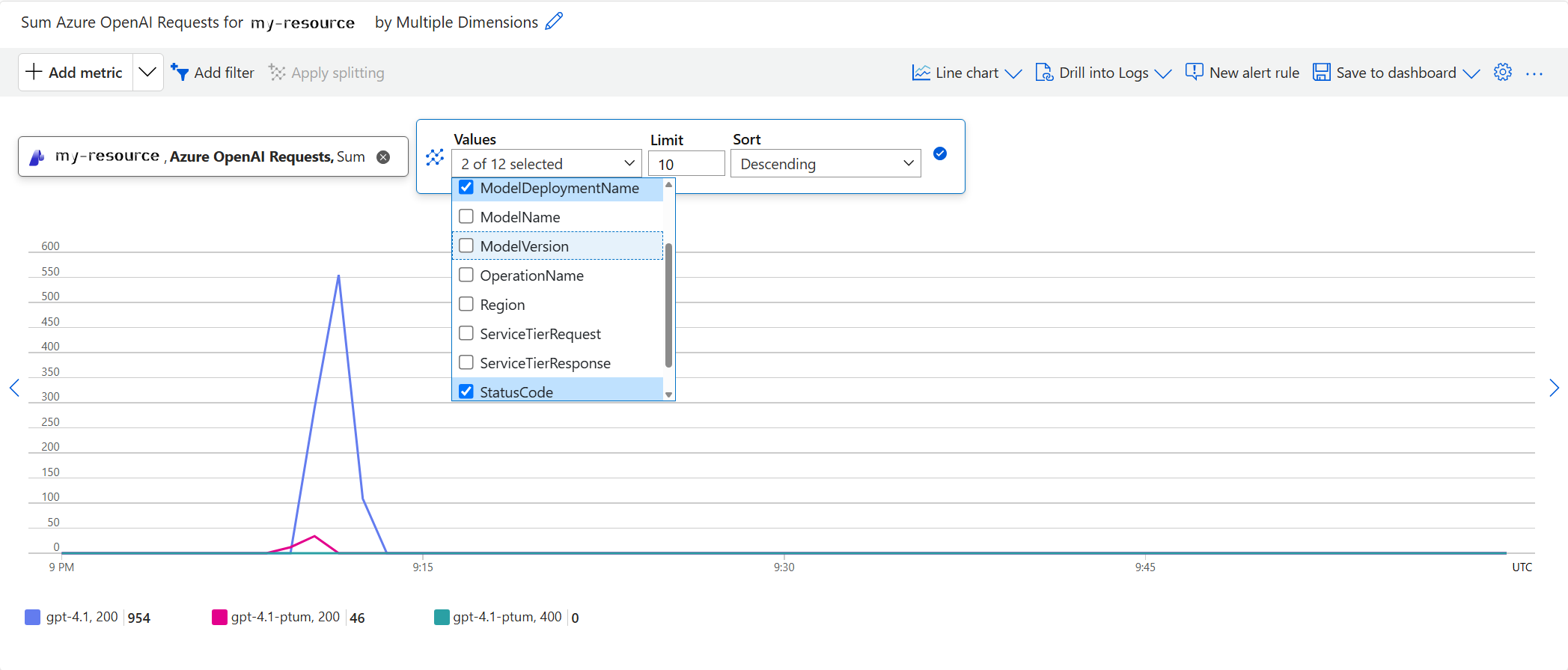
Seleccione Agregar filtro. En el cuadro de filtro, establezca la Propiedad en
ModelDeploymentNamey establezca los Valores en las implementaciones de modelos que desea ver.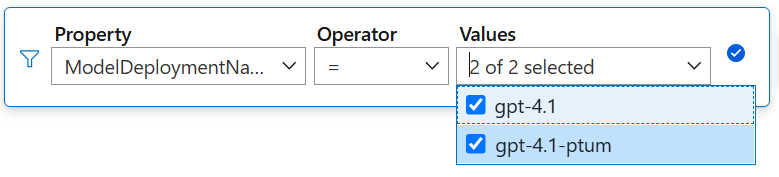
Cada solicitud que la implementación aprovisionada no puede atender (devolviendo
429,500o503) se redirige inmediatamente a la implementación de pago por uso utilizada para el desbordamiento, donde se procesa y se contabiliza como una respuesta200(gpt-4.1, 200 = 954). La línea de implementación aprovisionada (gpt-4.1-ptum, 200 = 46) refleja solo las solicitudes que atienden directamente, ya que las solicitudes desbordadas no se cuentan como429en la implementación aprovisionada. Para distinguir el tráfico excedente del tráfico directo en la implementación estándar, aplique la particiónIsSpillover, como se muestra en la sección siguiente.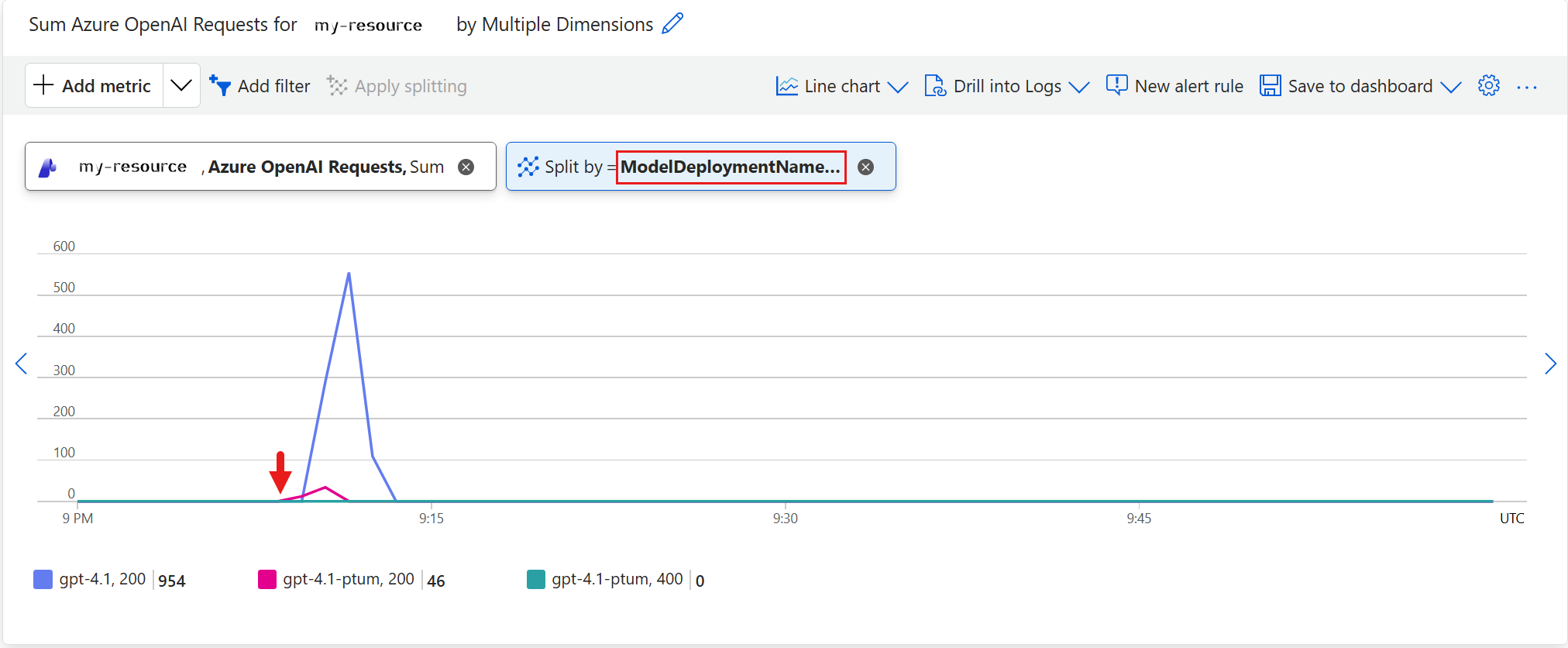



Ver métricas de desbordamiento
Aplicar la partición IsSpillover le permite ver qué solicitudes de su implementación estándar llegaron por desbordamiento desde una implementación aprovisionada. Las solicitudes desbordadas aparecen como registros en la implementación estándar con IsSpillover = True y su código de estado final (normalmente 200). No se contabilizan dos veces como 429 en el despliegue aprovisionado.
En el gráfico siguiente, la solicitud desbordada aparece como IsSpillover=True, gpt-4.1, 200 = 954 solo en la implementación estándar. La implementación aprovisionada no tiene ningún IsSpillover=True registro.
Captura de pantalla que muestra la división de desbordamiento en el portal de Azure.
Cuándo habilitar el desbordamiento
Para aprovechar al máximo la implementación aprovisionada, habilite el desbordamiento en todas las implementaciones aprovisionadas globales y de zona de datos. Con el desbordamiento, el servicio puede administrar automáticamente ráfagas o fluctuaciones en el tráfico. Esta funcionalidad reduce el riesgo de experimentar interrupciones cuando se usa completamente una implementación aprovisionada. Como alternativa, el desbordamiento se puede configurar por petición para proporcionar flexibilidad en distintos escenarios y cargas de trabajo. El desbordamiento también funciona con el Foundry Agent Service.
Cuando el efecto de desbordamiento se activa
Al habilitar el desbordamiento en una implementación o al configurarlo para una solicitud de inferencia determinada, el desbordamiento se inicia cuando se recibe un código de respuesta específico distinto de 200 como resultado de uno de estos escenarios:
Las unidades de rendimiento aprovisionadas (PTU) se usan por completo, lo que da como resultado un
429código de respuesta.Se envía una solicitud de token de contexto larga, lo que da como resultado un
400código de error. Por ejemplo, cuando se usangpt 4.1modelos de serie, PTU solo admite longitudes de contexto inferiores a 128K y devuelve HTTP 400.Los errores del servidor se producen al procesar la solicitud, lo que da como resultado código
500de error o503.
Cuando una solicitud da como resultado uno de estos códigos de respuesta no 200, Azure OpenAI envía automáticamente la solicitud desde su implementación aprovisionada a la implementación estándar para ser procesada.
Nota
Incluso si un subconjunto de solicitudes se enruta a la implementación estándar, el servicio prioriza el envío de solicitudes a la implementación aprovisionada antes de enviar solicitudes de uso por encima del límite a la implementación estándar. Esta priorización podría incurrir en latencia adicional.
Costo de desbordamiento
Dado que el desbordamiento utiliza una combinación de implementaciones aprovisionadas y estándar para gestionar las fluctuaciones del tráfico, la facturación del desbordamiento implica dos componentes:
En el caso de las solicitudes procesadas por la implementación aprovisionada, solo se aplica el costo de implementación aprovisionado por hora. No se incurre en costos adicionales para estas solicitudes.
En el caso de las solicitudes enrutadas a la implementación estándar, la solicitud se factura en el token de entrada asociado, el token almacenado en caché y las tasas de token de salida para la versión del modelo y el tipo de implementación especificados.