Visualización actual: Versión - Cambio a la versión del nuevo portal de Foundry
Versión - Cambio a la versión del nuevo portal de Foundry
Nota
Los vínculos de este artículo pueden abrir contenido en la nueva documentación de Microsoft Foundry en lugar de la documentación de Foundry (clásico) que está viendo ahora.
Una vez ajustado el modelo, puede implementarlo y usarlo en su propia aplicación.
Al implementar el modelo, se pone el modelo a disposición para realizar inferencias, lo que conlleva un cargo por alojamiento por hora. Sin embargo, los modelos optimizados se pueden almacenar en Microsoft Foundry sin costo alguno hasta que esté listo para usarlos.
Azure OpenAI proporciona opciones de tipos de implementación para modelos ajustados en la estructura de hospedaje que se ajusta a diferentes patrones empresariales y de uso: Standard, Global Standard (versión preliminar) y Pervisioned Throughput (versión preliminar). Obtenga más información sobre los tipos de implementación para modelos optimizados y los conceptos de todos los tipos de implementación.
Implementación del modelo optimizado
Importante
Para implementar modelos, debe tener asignado el rol Foundry Owner o cualquier rol con la acción /Microsoft.CognitiveServices/accounts/deployments/write.
Importante
Recientemente se ha cambiado el nombre de los roles RBAC de Foundry.
Foundry User, Foundry Owner, Foundry Account Owner y Foundry Project Manager se llamaban anteriormente Usuario de Azure AI, Propietario de Azure AI, Propietario de la cuenta de Azure AI y Administrador de proyectos de Azure AI. Es posible que siga viendo los nombres anteriores en algunos lugares mientras se implementa el cambio de nombre. El cambio de nombre no modifica los identificadores de rol y los permisos principales.
Para implementar el modelo personalizado, seleccione el modelo personalizado que se va a implementar y, a continuación, seleccione Implementar.
Se abre el cuadro de diálogo Implementar modelo . En el cuadro de diálogo, escriba el nombre de implementación y seleccione Crear para iniciar la implementación del modelo personalizado.
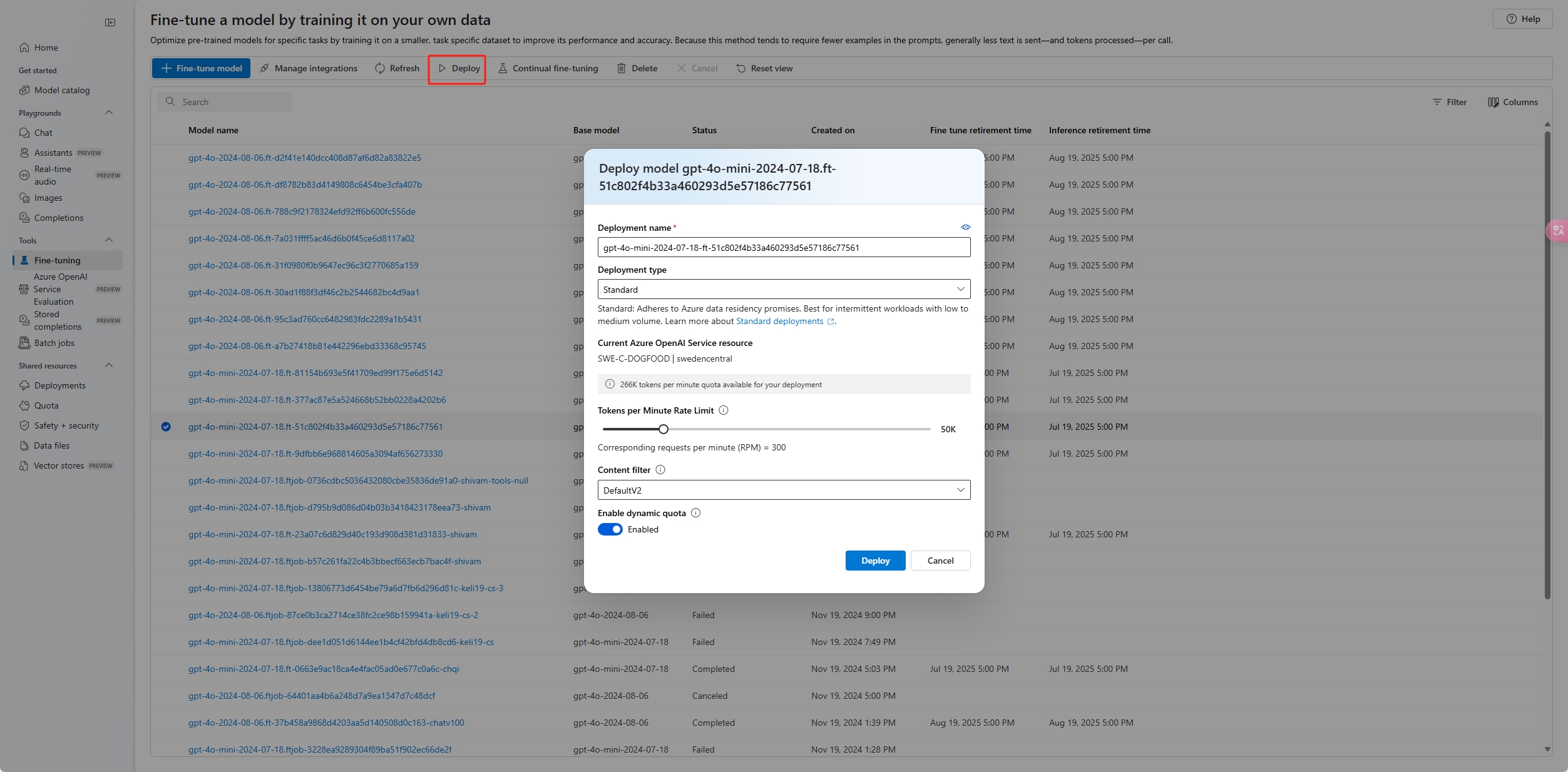
Puede supervisar el progreso de la implementación en el panel Implementaciones del portal de Foundry.
El portal no admite la implementación entre regiones. En su lugar, use el SDK de Python o la API REST.
import json
import os
import requests
token = os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name = "gpt-4.1-mini-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-21"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-4.1-mini-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
| Variable |
Definición |
| token |
Hay varias maneras de generar un token de autorización. El método más sencillo para las pruebas iniciales es iniciar el Cloud Shell desde el portal Azure. A continuación, ejecute az account get-access-token. Puede usar este token como token de autorización temporal para las pruebas de API. Se recomienda almacenarlo en una nueva variable de entorno. |
| suscripción |
El identificador de suscripción para el recurso de Azure OpenAI asociado. |
| grupo de recursos |
Nombre del grupo de recursos del recurso de Azure OpenAI. |
| nombre_del_recurso |
El nombre del recurso de Azure OpenAI. |
| model_deployment_name |
Nombre personalizado para la nueva implementación de modelos ajustados. Este es el nombre al que se hace referencia en el código al realizar llamadas de finalización de chat. |
| modelo afinado |
Recupere este valor de los resultados del trabajo de ajuste preciso del paso anterior. Su aspecto es similar a gpt-4.1-mini-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Debe agregar ese valor al deploy_data json. Como alternativa, puede implementar un punto de control pasando el identificador de punto de control, que aparece en el formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d. |
Implementación entre regiones
El ajuste preciso admite la implementación de un modelo ajustado en una región diferente a la de la ubicación en la que originalmente se ha ajustado el modelo. También puede implementar en otra suscripción o región.
Las únicas limitaciones son que la nueva región también debe admitir el ajuste preciso y, al implementar una suscripción cruzada, la cuenta que genera el token de autorización para la implementación debe tener acceso a las suscripciones de origen y de destino.
En el ejemplo siguiente, se implementa un modelo que fue optimizado en una suscripción/región y desplegado a otra.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name = "gpt-4.1-mini-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-21"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-4.1-mini-2025-04-14.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Para realizar la implementación dentro de la misma suscripción pero en distintas regiones, solo necesitaría que la suscripción y los grupos de recursos sean idénticos para las variables de origen y destino; solo los nombres de los recursos de origen y destino deberán ser únicos.
Implementación entre inquilinos
La cuenta que se usa para generar tokens de acceso con az account get-access-token --tenant debe tener permisos de colaborador de OpenAI de Cognitive Services para los recursos de Azure OpenAI de origen y destino. Deberá generar dos tokens diferentes, uno para el inquilino de origen y otro para el inquilino de destino.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
En el ejemplo siguiente se muestra cómo usar la API REST para crear una implementación de modelos para el modelo personalizado. La API REST genera un nombre para la implementación del modelo personalizado.
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
| Variable |
Definición |
| token |
Hay varias maneras de generar un token de autorización. El método más sencillo para las pruebas iniciales es iniciar el Cloud Shell desde el portal Azure. A continuación, ejecute az account get-access-token. Puede usar este token como token de autorización temporal para las pruebas de API. Se recomienda almacenarlo en una nueva variable de entorno. |
| suscripción |
El identificador de suscripción para el recurso de Azure OpenAI asociado. |
| grupo de recursos |
Nombre del grupo de recursos del recurso de Azure OpenAI. |
| nombre_del_recurso |
El nombre del recurso de Azure OpenAI. |
| model_deployment_name |
Nombre personalizado para la nueva implementación de modelos ajustados. Este es el nombre al que se hace referencia en el código al realizar llamadas de finalización de chat. |
| modelo afinado |
Recupere este valor de los resultados del trabajo de ajuste preciso del paso anterior. Su aspecto es similar a gpt-4.1-mini-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Debe agregar ese valor al deploy_data json. Como alternativa, puede implementar un punto de control pasando el identificador de punto de control, que aparece en el formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d. |
Implementación entre regiones
El ajuste preciso admite la implementación de un modelo ajustado en una región diferente a la de la ubicación en la que originalmente se ha ajustado el modelo. También puede implementar en otra suscripción o región.
Las únicas limitaciones son que la nueva región también debe admitir el ajuste preciso y, al implementar entre suscripciones, la cuenta que genera el token de autorización para la implementación debe tener acceso a las suscripciones de origen y de destino.
A continuación se muestra un ejemplo de implementación de un modelo que fue ajustado finamente en una suscripción/región a otra.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Para realizar la implementación entre la misma suscripción, pero diferentes regiones, solo tendría que tener grupos de recursos y suscripciones idénticos para las variables de origen y destino, y solo los nombres de recursos de origen y destino necesitarían ser únicos.
Implementación entre inquilinos
La cuenta que se usa para generar tokens de acceso con az account get-access-token --tenant debe tener permisos de colaborador de OpenAI de Cognitive Services para los recursos de Azure OpenAI de origen y destino. Deberá generar dos tokens diferentes, uno para el inquilino de origen y otro para el inquilino de destino.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
En el ejemplo siguiente se muestra cómo usar el CLI de Azure para implementar el modelo personalizado. Con el CLI de Azure, debe especificar un nombre para la implementación del modelo personalizado. Para obtener más información sobre cómo usar el CLI de Azure para implementar modelos personalizados, vea az cognitiveservices account deployment.
Para ejecutar este comando CLI de Azure en una ventana de consola, debe reemplazar el siguiente <placeholders> por los valores correspondientes para el modelo personalizado:
| Marcador de posición |
Valor |
|
<YOUR_AZURE_SUBSCRIPTION> |
Nombre o identificador de la suscripción de Azure. |
|
<YOUR_RESOURCE_GROUP> |
Nombre del grupo de recursos de Azure. |
|
<YOUR_RESOURCE_NAME> |
Nombre del recurso de Azure OpenAI. |
|
<SU_NOMBRE_DE_IMPLEMENTACIÓN> |
Nombre que desea usar para la implementación del modelo. |
|
<SU_IDENTIFICADOR_DEL_MODELO_AJUSTADO> |
Nombre del modelo personalizado. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Importante
Después de implementar un modelo personalizado, si en cualquier momento la implementación permanece inactiva durante más de 15 días, se elimina la implementación. La implementación de un modelo personalizado está inactiva si el modelo se implementó hace más de 15 días y no se realizaron finalizaciones de chat ni llamadas API de respuesta durante un período continuo de 15 días.
La eliminación de una implementación inactiva no elimina ni afecta al modelo personalizado subyacente. El modelo personalizado se puede volver a implementar en cualquier momento.
Como se describe en Precios de Azure OpenAI en modelos de Microsoft Foundry, cada modelo personalizado (ajustado a sus preferencias) que se implementa incurre en un coste de hospedaje por hora, independientemente de si se realizan finalizaciones o llamadas a la API de respuesta de chat al modelo. Para obtener más información sobre el planeamiento y la administración de costos con Azure OpenAI, consulte Plan y administración de costos para Azure OpenAI.
Uso del modelo optimizado implementado
Una vez implementado el modelo personalizado, puede usarlo como cualquier otro modelo implementado. Puede usar el área de juegos en el portal de Foundry para experimentar con la nueva implementación. Puede seguir usando los mismos parámetros con el modelo personalizado, como temperature y max_tokens, como puede con otros modelos implementados.

import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-4.1-mini-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure services support this too?"}
]
)
print(response.choices[0].message.content)
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure services support this too?"}]}'
CLI de Azure solo es para las operaciones del plano de control, como la creación de recursos y la implementación de model. Para las operaciones de inferencia, use la API REST o los SDK basados en lenguaje.
Almacenamiento en caché de mensajes
El ajuste preciso de Azure OpenAI admite el almacenamiento en caché de indicaciones con modelos seleccionados. El almacenamiento en caché de mensajes permite reducir la latencia general de las solicitudes y el costo de los mensajes más largos que tienen contenido idéntico al principio del mensaje. Para más información sobre el almacenamiento en caché de mensajes, consulte Introducción al almacenamiento en caché de mensajes.
Tipos de implementación
El ajuste de Azure OpenAI admite los siguientes tipos de implementación.
Estándar
Las implementaciones estándar proporcionan un modelo de facturación de pago por token con residencia de datos definida en la región implementada.
| Modelos |
Este de EE. UU. 2 |
Centro-norte de EE. UU. |
Centro de Suecia |
| o4-mini |
✅ |
|
✅ |
| GPT-4.1 |
|
✅ |
✅ |
| GPT-4.1-mini |
|
✅ |
✅ |
| GPT-4.1-nano |
|
✅ |
✅ |
| GPT-4o |
✅ |
|
✅ |
| GPT-4o-mini |
|
✅ |
✅ |
Estándar global
Las implementaciones optimizadas según el estándar global ofrecen el ahorro de costos, pero los pesos de modelo personalizados pueden almacenarse temporalmente fuera de la ubicación geográfica de tu recurso de Azure OpenAI.
Las implementaciones estándar globales están disponibles en todas las regiones de OpenAI de Azure para los siguientes modelos:
- o4-mini
- GPT-4.1
- GPT-4.1-mini
- GPT-4.1-nano
- GPT-4o
- GPT-4o-mini

Nivel de desarrollador
Las implementaciones optimizadas para desarrolladores ofrecen una experiencia similar a Global Standard sin una tarifa de hospedaje por hora, pero no ofrecen un Acuerdo de Nivel de Servicio de disponibilidad. Las implementaciones de desarrolladores están diseñadas para la evaluación candidata del modelo y no para su uso en producción.
Las implementaciones de desarrolladores están disponibles en todas las regiones de OpenAI de Azure para los siguientes modelos:
| Modelos |
Disponibilidad |
| o4-mini |
Todas las regiones |
| GPT-4.1 |
Todas las regiones |
| GPT-4.1-mini |
Todas las regiones |
| GPT-4.1-nano |
Todas las regiones |
Rendimiento aprovisionado
| Modelos |
Centro-norte de EE. UU. |
Centro de Suecia |
| GPT-4.1 |
|
✅ |
| GPT-4o |
✅ |
✅ |
| GPT-4o-mini |
✅ |
✅ |
Las implementaciones ajustadas de rendimiento aprovisionado ofrecen un rendimiento predecible en las aplicaciones y los agentes sensibles a la latencia. Usan la misma capacidad de rendimiento aprovisionado regional (PTU) que los modelos base, por lo que si ya tiene cuota de PTU regional, puede implementar el modelo optimizado en regiones de soporte técnico.
Limpieza de la implementación
Para eliminar una implementación, use la API REST Deployments - Delete y envíe una ELIMINACIÓN HTTP al recurso de implementación. Al igual que con la creación de implementaciones, debe incluir los parámetros siguientes:
- identificador de suscripción de Azure
- Nombre del grupo de recursos de Azure
- nombre de recurso de Azure OpenAI
- Nombre de la implementación que se va a eliminar
A continuación se muestra el ejemplo de la API REST para eliminar una implementación:
curl -X DELETE "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>"
También puede eliminar una implementación en el portal de Foundry o usar CLI de Azure.
Pasos siguientes


